
El crawling en SEO es el proceso mediante el cual los motores de búsqueda descubren y navegan por las páginas web. Este proceso es realizado por crawlers que recorren la web siguiendo enlaces.
Comprender qué es el crawling SEO y su funcionamiento es fundamental para optimizar la visibilidad de un sitio web. Sin este paso, una página no puede ser indexada ni aparecer en los resultados de búsqueda.
¿Qué es el Crawling en SEO?
El crawling es un proceso crucial en el mundo del SEO, dado que permite a los motores de búsqueda descubrir y acceder a nuevas páginas web. Además, actualizar el contenido de las existentes. A continuación se presentan los aspectos clave que forman parte de este concepto.
En ese sentido, el crawling se refiere a la técnica utilizada por los motores de búsqueda para rastrear la web. Esto, mediante la ejecución de programas conocidos como «crawlers» o «bots».
Estos bots recorren los enlaces dentro de las páginas web, siguiendo una estructura jerárquica para descubrir el contenido disponible. Cada vez que un crawler accede a una página, recopila información que se utilizará posteriormente para la indexación.
Funcionamiento del Crawling
El funcionamiento del crawling involucra varios pasos precisos que permiten la recopilación eficiente de datos. El proceso se descompone en las siguientes etapas:
- Descubrimiento de URLs: Los crawlers inician su recorrido encontrando URLs a través de enlaces en otras páginas previamente rastreadas. Este descubrimiento es esencial para identificar páginas nuevas y actualizadas.
- Análisis de la estructura del sitio: Al acceder a una web, el crawler analiza la organización de su contenido. Esto incluye la jerarquía de las páginas y la presencia de enlaces internos que facilitan la navegación.
- Extracción de contenido: Durante el rastreo, el programa captura el texto y otros elementos disponibles en cada página, lo cual es fundamental para el siguiente proceso, que es la indexación.
Importancia del crawling en el posicionamiento SEO
El crawling es vital puesto que permite que una página web sea reconocida por los motores de búsqueda. Sin este proceso, un sitio puede volverse invisible, ya que los buscadores no podrían acceder a su contenido. Los puntos a considerar sobre esta importancia incluyen:
- Un sitio debe ser rastreado para que su contenido sea indexado y, por lo tanto, pueda aparecer en los resultados de búsqueda.
- El crawling permite la actualización frecuente de contenido, crucial para mantener la relevancia en el ranking de búsqueda.
Diferencia entre Crawling e Indexación
A menudo, se confunden los términos crawling e indexación, aunque representan dos procesos distintos en el ecosistema web.
El crawling es el primer paso en el que los bots descubren las páginas, mientras que la indexación consiste en almacenar y clasificar la información extraída durante el proceso de crawling.
No todas las páginas que son rastreadas son necesariamente indexadas, lo que subraya la importancia de cumplir con los estándares de calidad que determinan la relevancia del contenido para los usuarios.
Cómo funcionan los Crawlers
Los crawlers son programas automatizados que recorren la web para descubrir y recopilar información sobre las páginas disponibles. Este proceso es esencial para que los motores de búsqueda mantengan sus índices actualizados y ofrezcan resultados de búsqueda relevantes.
Tipos de Crawlers

Existen diferentes tipos de crawlers, cada uno diseñado para conocer y analizar varios tipos de contenido en la web. A continuación se presentan los principales tipos:
- Crawlers generales: Estos son los que se utilizan para navegar por el contenido general de la web. Su función es identificar y recuperar información de diversas páginas.
- Crawlers especializados: Este tipo se centra en áreas específicas, como imágenes, noticias o anuncios. Están optimizados para capturar contenido particular y mejorar su clasificación en los motores de búsqueda.
- Crawlers de archivos: Se especializan en el acceso a documentos y archivos, como PDFs o archivos multimedia, para indexar su contenido.
El rol del Googlebot
El Googlebot es el crawler principal utilizado por Google. Este robot tiene varias funciones que son cruciales para el proceso de búsqueda. Su papel incluye:
- Exploración de sitios web: Googlebot explora el contenido de los sitios web para identificar nuevos recursos y actualizaciones en las páginas existentes.
- Evaluación de contenido: Analiza la calidad y relevancia del contenido para determinar la posición que debe ocupar en los resultados de búsqueda.
- Adaptación a dispositivos: Googlebot tiene versiones tanto para computadoras de escritorio como para dispositivos móviles, lo que le permite ofrecer resultados óptimos en cualquier plataforma.
Estrategias de rastreo de Google
Google implementa varias estrategias de rastreo para optimizar la eficiencia de su crawler. Estas estrategias incluyen:
- Mapas del sitio (Sitemaps): Googlebot utiliza mapas del sitio para entender la estructura de un sitio y localizar páginas importantes de manera más efectiva.
- Prioridad en el rastreo: Algunos sitios más relevantes o de mayor autoridad suelen ser rastreados con mayor frecuencia. Esto permite que Google obtenga información fresca y actualizada.
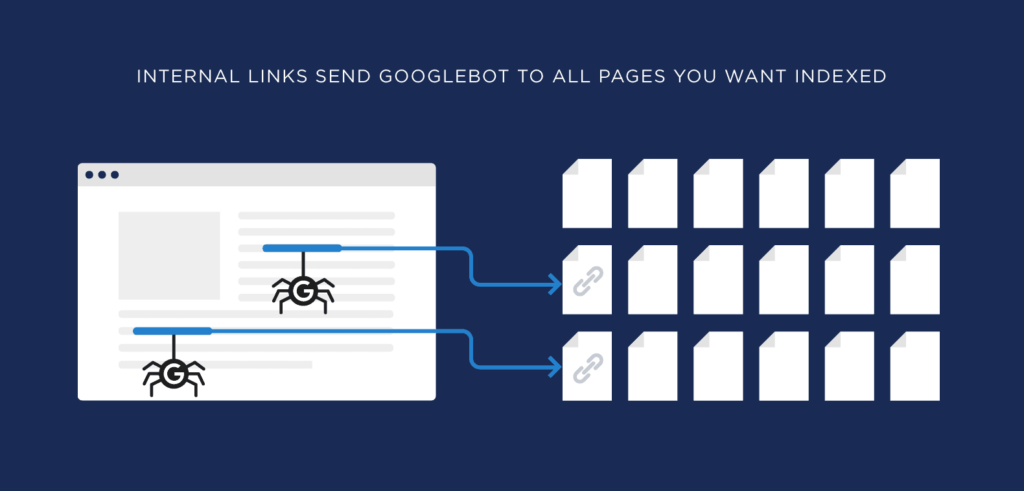
- Uso de enlaces: Los enlaces internos y externos son esenciales para que Googlebot descubra nuevas páginas. Cuanto más fácil sea navegar entre las distintas secciones de un sitio, más eficientes serán los rastreos.
Factores que influyen en el Crawling
Existen varios elementos clave que pueden afectar la eficacia del crawling. Comprender estos factores es fundamental para optimizar la capacidad de los motores de búsqueda para acceder e indexar el contenido de una página web.
Descubrimiento de URLs
El descubrimiento de URLs es un componente esencial del proceso de crawling. Los crawlers necesitan encontrar enlaces a nuevas páginas para rastrearlas. Los métodos más comunes para esto incluyen:
- Enlaces de otros sitios web: Los enlaces de páginas ya indexadas proporcionan un camino directo a nuevas URLs.
- Promoción en redes sociales: Compartir enlaces en plataformas sociales puede ayudar a los motores de búsqueda a encontrarlas.
- Publicaciones de blogs y artículos: Los enlaces desde contenido relevante pueden ser una fuente valiosa para el descubrimiento de nuevas páginas.
Análisis de la estructura del sitio web
La forma en que un sitio web está organizado puede influir considerablemente en la efectividad del crawling. Los motores de búsqueda analizan la estructura para entender la relación entre las páginas y su relevancia. Algunos aspectos clave incluyen:
Uso de enlaces internos
Implementar una estrategia de enlaces internos robusta permite que los crawlers naveguen fácilmente por el sitio. Esto ayuda a priorizar el contenido más importante y a mejorar la distribución de autoridad entre las páginas.
Utilidad del mapa del sitio
Un mapa del sitio bien diseñado facilita el rastreo y la indexación de todas las páginas de un sitio web. Este archivo proporciona una guía clara a los crawlers sobre cómo se organiza el contenido y cuáles son las páginas más relevantes.
Extracción de contenido
Durante el proceso de crawling, los motores de búsqueda extraen el contenido de las páginas para evaluarlo durante la indexación. La calidad, relevancia y formato del contenido afectan el éxito del crawling. Las características que los crawlers buscan incluyen:
- Texto claro y conciso: Un contenido bien estructurado permite una mejor comprensión por parte de los motores de búsqueda.
- Etiquetas HTML adecuadas: El uso correcto de etiquetas ayuda a los crawlers a identificar fácilmente el contenido clave en una página.
Problemas comunes que bloquean el Crawling SEO
Existen varios problemas que pueden impedir que los crawlers accedan a un sitio web. Algunos de los más comunes son:
- Errores 404: Páginas que no existen generan frustración en los crawlers y pueden llevar a que el sitio sea subestimado.
- Bloqueos en el archivo robots.txt: Limitar el acceso a ciertas secciones del sitio sin razones justificadas puede afectar la indexación.
- Páginas sin enlaces: Las URLs que no son accesibles a través de ningún enlace interno no podrán ser descubiertas por los crawlers.
El Crawl Budget y su impacto en el SEO
El crawl budget es un aspecto crucial en la optimización para motores de búsqueda, ya que determina cuántas páginas de un sitio pueden ser rastreadas por los crawlers en un período determinado. A continuación se exploran sus componentes y relevancia.
¿Qué es el Crawl Budget?

El crawl budget se refiere a la cantidad de recursos que un motor de búsqueda como Google asigna para rastrear un sitio web.
Este presupuesto no es igual para todos los sitios. Depende de una serie de factores, entre los que se incluyen la autoridad del dominio, popularidad y calidad del contenido.
Un crawl budget eficiente permite que los motores de búsqueda accedan a las páginas más relevantes de un sitio, mientras que un presupuesto de rastreo limitado puede resultar en la omisión de contenido valioso.
Por lo tanto, es esencial que los propietarios y administradores de sitios web comprendan este concepto para maximizar su visibilidad online.
Cómo optimizar el Crawl Budget
Existen varias estrategias que pueden ayudar a optimizar el crawl budget, permitiendo que más páginas sean indexadas y mejorando, en última instancia, el rendimiento en los resultados de búsqueda. Algunas de estas prácticas incluyen:
- Implementar un diseño de sitio limpio y organizado que facilite la navegación.
- Crear y mantener un sitemap actualizado que sirva como guía para los crawlers.
- Eliminar páginas obsoletas o de bajo valor que puedan consumir recursos sin proporcionar beneficios.
- Priorizar la optimización de la velocidad del sitio, ya que un servidor rápido permite a los crawlers acceder a más páginas en menos tiempo.
Factores que afectan el Crawl Budget
Hay múltiples elementos que influyen en el crawl budget de un sitio web. Algunos de los más significativos son:
- Tiempo de respuesta del servidor: Un tiempo de carga lento puede frustrar a los crawlers y reducir el número de páginas que pueden ser rastreadas.
- Errores 4xx y 5xx: Las URLs que generan errores no solo consumen crawl budget, sino que también dificultan la tarea de los bots al determinar el estado del sitio.
- Páginas aisladas: Las páginas que no tienen enlaces internos que las conecten con otras partes del sitio son más difíciles de descubrir y, como resultado, pueden no ser rastreadas adecuadamente.
- Frecuencia de actualización de contenido: Los sitios que actualizan su contenido regularmente tienden a ser rastreados con mayor frecuencia, ya que los motores de búsqueda tienen más motivos para regresar y revisar cambios.
Optimización del Crawling para SEO
La optimización del crawling es un aspecto esencial para garantizar que las páginas web sean fácilmente accesibles para los motores de búsqueda. Un enfoque adecuado permite que los crawlers naveguen de manera eficiente y descubran contenido relevante.
Importancia de un diseño web optimizado
Un diseño web optimizado juega un papel crucial en la facilidad de rastreo de un sitio.
Una estructura clara y una presentación lógica de la información ayudan a los crawlers a navegar sin dificultades, lo que aumenta las posibilidades de que todas las páginas sean indexadas. Elementos clave de un diseño optimizado incluyen:
- Navegabilidad intuitiva.
- URLs limpias y descriptivas.
- Uso adecuado de etiquetas HTML que definan jerarquías y relaciones entre contenido.
Mejorar la velocidad de carga de la página
La velocidad de carga de una página web afecta directamente la frecuencia de rastreo. Un sitio que carga rápidamente permite a los crawlers acceder a más contenido en menos tiempo. Estrategias para mejorar la velocidad incluyen:
- Optimización de imágenes para reducir su tamaño.
- Minificación de archivos CSS y JavaScript.
- Implementación de técnicas de caché para mejorar tiempos de respuesta.
Evitar bloqueos indebidos a los crawlers
Es habitual que algunos propietarios de sitios web apliquen bloqueos sin darse cuenta de que están afectando su visibilidad. Estos bloqueos pueden ocurrir a través de:
- Archivos robots.txt mal configurados que impiden el acceso a contenido vital.
- Etiquetas meta «noindex» que limitan la indexación.
Es crucial revisar y actualizar estos ajustes para asegurar que los crawlers tengan acceso a todas las áreas relevantes del sitio.
Frecuencia de actualización de contenido
Mantener el contenido fresco y actualizado es otro punto importante para el crawling. Los motores de búsqueda suelen rastrear más frecuentemente aquellas páginas que reflejan cambios recientes. Algunas prácticas recomendadas son:
- Actualizar artículos y publicaciones con nueva información.
- Agregar contenido adicional o relacionado para mantener la relevancia.
El incremento en la actualización de contenido puede motivar a los crawlers a regresar con mayor regularidad, mejorando así la exposición del sitio en los resultados de búsqueda.
Herramientas para monitorear y mejorar el Crawling
Las herramientas adecuadas son fundamentales para supervisar y optimizar el proceso de crawling. Permiten identificar problemas, analizar el comportamiento de los crawlers y ajustar la estrategia SEO en consecuencia.
Uso de Google Search Console
Google Search Console es una de las herramientas más imprescindibles para cualquier propietario de un sitio web.
Fue diseñada para ayudar a los administradores a comprender cómo Google interactúa con sus páginas. Ofrece información valiosa sobre el rendimiento del site y el estado del crawling.
- Monitoreo de errores: Proporciona informes sobre errores de rastreo, lo que permite a los usuarios abordar problemas específicos que puedan impedir que los crawlers accedan a contenido importante.
- Indexación: Permite inspeccionar cómo se indexan las páginas, mostrando detalles sobre el estado de cada URL y ayudando a detectar problemas de indexación.
- Optimización del Sitemap: Facilita la gestion del sitemap, asegurando que se envíen las URL correctas para ser rastreadas y que los cambios se reflejen rápidamente en Google.
Análisis de Logs del servidor
El análisis de logs del servidor proporciona una visión profunda sobre cómo los crawlers interactúan con un sitio web. Los logs registran cada visita de los crawlers y pueden revelar patrones en sus comportamientos.
- Identificación de accesos: Ayuda a identificar qué páginas han sido visitadas por los crawlers y con qué frecuencia, lo que permite evaluar si el contenido más importante está siendo rastreado adecuadamente.
- Detección de problemas: Los logs pueden mostrar errores de acceso, indicando qué URL presentan problemas, lo que permite implementar soluciones a tiempo.
- Análisis de comportamiento: Estudia el comportamiento de los bots respecto a la estructura del sitio, ayudando a ajustar el diseño para optimizar el crawling.
Herramientas de terceros para auditar el Crawling
Existen numerosas herramientas de terceros que se dedican a auditar el crawling, proporcionando análisis más detallados y personalizados. Pueden complementar los datos obtenidos a través de Google Search Console y logs del servidor.
- Screaming Frog: Esta herramienta permite rastrear los sitios web para identificar problemas técnicos, como enlaces rotos o redirecciones incorrectas, que pueden afectar el crawling.
- Sitebulb: Ofrece un análisis visual del sitio, facilitando la identificación de problemas de estructura y optimización que pueden mejorar el rendimiento del crawling.
- Ahrefs y SEMrush: Estas herramientas ayudan a analizar el perfil de enlaces y el comportamiento de SEO en general, permitiendo a los usuarios ajustar sus estrategias basándose en información recopilada sobre el crawling.





